PifPaf: Composite Fields for Human Pose Estimation - CVPR 2019 论文解读
arxiv地址: https://arxiv.org/abs/1903.06593
github地址: https://github.com/vita-epfl/openpifpaf
今年的CVPR19的论文最近已经在CVF Openaccess 网站上放出来了。不知为何,我对今年的新鲜出炉的国际计算机视觉模式识别顶会(CVPR)论文的期待感有所降低。
我主要是研究人体姿态估计问题的,还记得去年18CVPR论文出来的时候,我把所有有关的人体姿态估计的论文的题目和概要大致都看了,得出的一个浅显的结论就是:3D姿态估计、密集姿态估计要火了。这是因为在去年CVPR18的论文中,出现了大量的3D有关的论文而少有2D姿态估计研究(比如在MPII, COCO keypoint数据集上的很少,可能搞2d姿态的都去发了ECCV18)。
而今年19CVPR的姿态估计好像又呈现出一次小爆发,2D,3D,4D,5D,6D,..... 出现了。
COCO数据集上的性能又来到了一次新高:似乎74mAP已经被突破了。各位研究者们,是不是感觉到了精度上、性能上的压力。。。深度调参还是方法革新,这是个问题. What's your problem?
众多论文中,我先阅读了这篇,OpenPIFPAF。 因为它好像是茫茫论文海中出现的那个最与众不同的一篇,吸引我去一探Ta的全貌与究竟,为什么呢?我先放在心里不说,然后强行进入正题。
我感觉OpenPifpaf继承了很多优秀的姿态估计论文的工作:
- openpose
- G-RMI
- PersonLAB
并致力于解决几个棘手的问题:
- Bottom-up的多人姿态解析问题
- 自动驾驶中,图像中小尺寸人体的问题
文章目录
先前的工作:G-RMI
G-RMI 是google的一篇自上而下处理姿态估计问题的开篇
通过Faster-RCNN检测得到包含单个人体的bounding box,然后再进行单人姿态估计

本论文在预测$K$个表示置信度的heatmaps之外,又引入了offset fields的方法,用$2\times K$个heatmaps表示,即每个heatmap的位置上预测一个$F_k(x_{i})=l_k-x_{i}$的位移偏量,用$l_k$来表示真实位置,其中$x_i,k \in \mathbb{Z}_+^2$ $i,k$表示位置索引和关键点类型。

After generating the heatmaps and offsets, we aggregate them to produce highly localized activation maps $f_{k}\left(x_{i}\right)$ as follows:
其中第三个公式中的$G(\cdot)$论文中说它是双线性插值核,在今年19CVPR的openpifpaf论文,又再次利用这个公式,不过用一个高斯核来代替了$G(\cdot)$函数,我从中推断出这是起到了平滑取值的作用,就像我们在构造产生grountruth heatmaps那样的做法。下面的$\pi R^{2}$是一个归一化,和高斯核那样类似。
训练loss是:
$\lambda_{h}=4$ and $\lambda_{o}=1$ is a scalar factor to balance.
We use a single ResNet model with two convolutional output heads. The output of the firshead passes through a sigmoid function to yield the heatmap probabilities $h_{k}\left(x_{i}\right)$ for each position $x_{i}$ and each keypoint $k$ . The training target $\overline{h}_{k}\left(x_{i}\right)$ is a map of zeros and ones, with $\overline{h}_{k}\left(x_{i}\right)=1$ if $\left\|x_{i}-l_{k}\right\| \leq R$ and 0 otherwise. The corresponding loss function $L_{h}(\theta)$ is the sum of logistic losses for each position and keypoint separately.
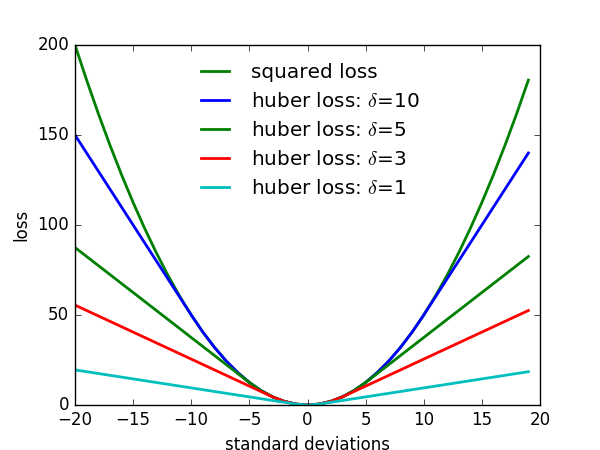
where $H(u)$ is the Huber robust loss, $l_{k}$ is the position of the $k$ -th keypoint, and we only compute the loss for positions $x_{i}$ within a disk of radius $R$ from each keypoint.
Huber robust loss的函数图像为:
OpenPIFPAF
在G-RMI、PersonLab的基础上,引入了PAF和PIF 复合结构,实际上具备显式含义的向量场。
即在图像每个location的像素位置,寄托更多的复合含义,编码具有直观含义的向量
PIF针对每一种类型的关键点,PAF针对每一种关联肢体(两个有关part的连接连线)
对于COCO,有17个关键点,19个连接(论文默认设置)
PIF
PIF是个$K\times H \times W \times 5$的结构, K表示关键点的数量,COCO为17个
They are composed of a scalar component for confidence, a vector component that points to the closest body part of the particular type and another scalar component for the size of the joint. More formally, at every output location spread $b$ (details in Section 3.4$)$ and a scale $\sigma$ and can be written as
因为作者主要针对小尺寸人体图片,那么得到的置信度图 confidence map 是非常粗糙的,为了进一步地提升confidence map 的定位精度,作者使用偏量位移maps 来提升confidence map 的分辨率,得到一个高分辨率的confidence map,如下公式:
这个公式我发现,很大程度上借鉴了G-RMI中的上述公式。用一个未归一化的高斯核,以及可学习的范围因子$\sigma$来代替G-RMI中的双线性插值核以及归一化的分母。这么做的缘故是,我认为是,想保证不论在何种尺寸(量化等级下)都能克服量化误差的影响,因为heatmap是基于grid的,离散的取值,而真实的位置是不基于grid,并且是连续的位置,我通过预测真实位置与grid位置的偏移、以及grid上的置信度,就能进而获知真实的精确位置。(我个人理解这样的好处就是,定位精度是float级别的,而不是int级别的,这个实际上在小尺寸的图像上是非常重要的一种策略。这种思想源自于G-RMI, 我认为这是一个解决量化误差问题的非常好的方式, 像SimpleBaseline,CPN运用取1/4偏移的方式,是一种人为的假设.)

PAF
PAF是个$N\times H \times W \times 7$的结构, N表示关联肢体的数量,默认为19,
作者使用的bottom-up的方法,必然要解决:关联检测的关键点的位置形成隶属的人体的这一问题,就必须用一定的表示手段和策略来实现。
作者提出了PAF,来将关键点连接一起形成姿态。
在输出的每个位置,PAFs预测一个置信度、两个分别指向关联一起的两个part的向量、两个宽度。用下面来表示:
作者接下来说了这样一句话,
Both endpoints are localized with regressions that do not suffer from discretizations as they occur in grid-
based methods. This helps to resolve joint locations of close-by persons precisely and to resolve them into
distinct annotations。 我目前的理解是,两个端点定位的回归,不再受困于 grid-based方法中出现的离散化问题!这就帮助对于离得很近的关键点精确位置,并区分它们的标注。
在COCO数据集,一共有19个连接关联两种类型的关键点。算法在每个feature map的位置,构造PAFs成分时,采用了两步:
首先,找到关联的两个关键点中最近的那一个的位置,来决定其向量成分中的一个。
然后,groundtruth pose决定了另外一个向量成分。第二个点不必是最近的,也可以是很远的。
一开始我没有,怎么理解这么做的含义。后来意识到,这样就相当于,对于每一种类型的关联肢体,比如左肩膀和左屁股连接。对应的PAF中,每个位置都会优先确定理它最近的关键点的位置(考虑多个人体的情况下),然后指向另外一端的向量就自然得到了。
并且在训练的时候,向量成分所指向的parts对必须是相关联的,每个向量的x,y方向必须指向同一个关键点的。
Adaptive Regression Loss
定位偏差可能对于大尺寸人体来讲,是小的影响,但是对于小尺寸人体,这个偏差就会成为主要的问题。本研究通过引入尺度依赖到$L_1 - type$的loss函数里,
Greedy Decoding
通过PIF和PAF来得到poses。这个快速贪心的算法过程和PersonLab中的相似。
一个姿态由一个种子点(高分辨率PIF的最高响应位置)开始,一旦一个关键点的估计完成,决策就是最终不变的了。(贪心)
A new pose is seeded by PIF vectors with the highest values in the high resolution confidence map $f(x, y)$ defined in equation $1 .$ Starting from a seed, connections to other joints are added with the help of PAF fields. The algorithm is fast and greedy. Once a connection to a new joint has been made, this decision is final.
Multiple PAF associations can form connections between the current and the next joint. Given the loca-
tion of a starting joint $\vec{x},$ the scores $s$ of PAF associations a are calculated with
这个$s(\mathbf{a},\vec{x})$表示每个location属于part association的得分,得分越高,代表这个更有可能是part association区域部分那么,如果$s(\mathbf{a},\vec{x})$越大,那么就期望$a_c$越大,$\left(-\frac{\left\|\vec{x}-\vec{a}_{1}\right\|_{2}}{b_{1}}\right)$越大,$\frac{\left\|\vec{x}-\vec{a}_{1}\right\|_{2}}{b_{1}}$越小,那么就期望PAF某位置的$\mathbf{a}$ 对应的$\mathbf{a}=\left\{a_{c}^{i j}, a_{x 1}^{i j}, a_{y 1}^{i j}, a_{b 1}^{i j}, a_{x 2}^{i j}, a_{y 2}^{i j}, a_{b 2}^{i j}\right\}$向量中, 其指向的端点1和当前种子点距离最近, 并且期望该位置指向的另外一个端点2的置信度响应高, 这些期望和该位置是属于这两个关键点(端点)连接肢体的期望是一致的. 一旦我们的初始种子点确立后,我们就可以根据预测的PAF找到其关联的肢体区域和另外一个关键点位置,作为下一次的寻找的种子点.然后,重复这个过程,直到该种子点对应的人体全部找到.(这实际运用了人体躯干的连通性的潜在知识). 作者提倒:
To confirm the proposed position of the new joint, we run reverse matching. This process is repeated until a full pose is obtained. We apply non-maximum suppression at the keypoint level as in [34]. The suppression radius is dynamic and based on the predicted scale component ofthe PIF field. We do not refine any fields neither during training nor test time.
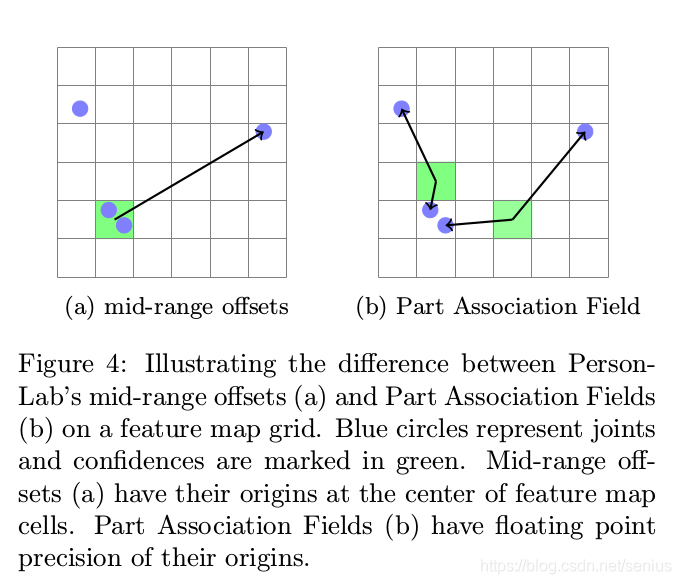
这个设计是非常非常巧妙的,因为我们在构造PAF的时候,请注意到,$(a_{x1},a_{y1})$ 是PAF输出map的某位置$\mathbf{a}$最近的关键点的位置(请看Figure 4b),以此来判断离该位置$\mathbf{a}$最近的关键点是不是$\vec{x}$。如果当前$\vec{x}$和$(a_{x1},a_{y1})$的距离就可以作为当前位置是不是指向$\vec{x}$的判断,因为如果两点重合的话,距离为0,指数取值为最大值1. 并且该位置对应的另外一个端点的取值具有高响应, 那么这就意味着:
$s(\mathbf{a}, \vec{x})$的髙得分位置,很有可能处在指向$\vec{x}$端点的肢体关联部分的区域!
换句话说:
$PIF$是提供候选的关键点。$s(\mathbf{a}, \vec{x})$得分公式,利用$PAF$预测值计算在输出feature map每一个位置的得分,来判断两种关键点之间的连接(如左肘部和左手腕),因为涉及到多人,(参考OpenPose,对于单个人体的单个肢体连接,只有一种连接是合理的),论文提到的To confirm the proposed position of the new joint, we run reverse matching,我认为就是来确定某人体的某个肢体连接的唯一性、合理性的手段,具体还是要看源码。
找到$(a_{x2},a_{y2})$的位置(通过髙响应$s(\mathbf{a}, \vec{x})$)的位置?还是通过PIF,PAF的预测值得到?这个目前有待考证,我在后面会阅读实现源码,继续更新博客)
那么,通过这样的一个贪心的快速算法, 我们根据初始的某个关键点就能同时确立多个人体位置
占位符
... to be continued
思考与总结
注:可以看出这一系列的论文(GRMI,PersonLab,Openpifpaf,part-based)相比与只针对网络结构进行改进(Seu-pose,SimpleBaseline,HRNET)的文章看,更加关注几何关系上的问题以及网络的输出表示形式。PersonLab,Openpifpaf面对更加有挑战性的BBOX-FREE方法,以及小尺寸,遮挡问题进行处理,确确实实能给人持续往下深入的启示和实际应用的潜力。针对改网络结构的文章,譬如HRNET,SEU-POSE,SIMPLEBASELINE,CPN等等,致力于寻找最有的卷积结构设计,而不怎么关注一些棘手的问题(用模型本身的能力来克服),为姿态估计行业引领性能的标准,并不断去探索神经网络结构可能发挥的极限。前者更适合去研究新方法,突破现有检测器约束的姿态估计框架,去挑战多人姿态估计的难题,后者给我们提供了,固有框架内可以进一步提升性能的很多实用的经验和技巧,让我们更加洞察神经网络的结构的特性,并充分利用神经网络结构设计的潜在能力。
哪个才能解决人体姿态估计的本质问题呢?