初步想法与设计¶
噪声问题、对抗样本的存在在图像分类任务会有深刻的影响。同样,这些问题也会影响到计算机视觉涉及到回归任务的学习,比如目标检测,关键点的定位。回归任务中其实也在包含了分类的内涵在里面,除此外,还需要确定位置信息,即what it is and where it is。而噪声样本的存在,依旧会影响DNN对此类问题的数据流形的决策边界的判断。
因为深度神经网络的强大的表示能力和记忆特性$[1]$在训练时能够拟合无论来自数据还是标签的噪声,会让模型学到过于复杂的假设,而减缓收敛,失去指定目标的泛化识别能力。又因为深度神经网络模型优先学到简单的模式,在训练早期碰到难度较大的样本,不利于寻找数据流形中明显的决策边界,所以我们在训练前期应该让模型看到更简单一些的样本,保留一小部分难样本对梯度回传的贡献。这个想法包含了AdBoost中用数据来决定模型学习的理念或者说是OHEM(在线难例挖掘)的逆向思维。在训练的后期,我们再减少模型对困难样本学习的限制,同时,在拟合较为困难甚至带有噪声的样本时,避免对之前学习的样本的遗忘。
在以上论述基础上,我大致想出Meta-Batch的方法:该方法是一个简单高效的方式,它类似于在线学习,但又不完全等价于它,因为每个周期间的batch学习不再像传统mini-batch那样保持独立,而是通过meta属性的取值而存在前后关联,使得模型对每个迭代学习具有记忆性,即每次迭代学习所参考的包括了模型的过去历史学习经验,涉及到了元学习meta-learning的范畴,即learn-to-learn,而属性的设计又有部分人工干预,这部分我主要还是受到神经网络的记忆特性的启发。
具体方法是:
在训练模型的每个周期内,我们规定每个样本最多只被学习一次。我们为每个样本,建立唯一的index,然后为每个样本index关联Meta属性,这里我们仅仅定义了难度系数D和遗忘程度F这两个属性,它不是超参数,这两个属性随周期性的学习发生变化。
- 难度系数D,由历史的学习经验和当前阶段的loss获取,来决定在每个batch学习中,我们是否要根据样本的学习难度,舍弃此实例对梯度反向传播的贡献。原则是:训练早期舍弃较难的样本。
- 遗忘程度F,由历史的学习经验获取,主要来决定我们是否要重拾一些被难度系数准则所舍弃的实例,来进一步增强模型的鲁棒性。原则是:训练后期额外加入被舍弃次数较多的样本,另外,选择部分较易的样本使模型继续保持泛化能力。
前者在训练前期发挥主要作用,后者在训练中后期,模型有将强的表示能力后,发挥主导的作用。
此理念指导下可以设计出不同类型和性质的属性,其定义方式也可以是灵活的。
在每个周期中batch迭代阶段,我们为batch中的每个样本的loss,然后我们根据loss和周期epoch重新计算该样本的难度系数D和F,决定哪些样本的loss需要梯度回传,哪些被抛弃。其中,D和F的计算方式需要精心考虑。我们设计了如下算法。
1Understanding deep learning requires rethinking generalization. (ICLR), 2017.
2Arpit, Devansh et al. “A Closer Look at Memorization in Deep Networks.” ICML (2017)
import plotly.graph_objs as go
fig = go.FigureWidget()
# Display an empty figure
fig
# Add a scatter chart
fig.add_scatter(y=[2, 1, 4, 3])
# Add a bar chart
fig.add_bar(y=[1, 4, 3, 2])
# Add a title
fig.layout.title = 'Hello FigureWidget'
fig
import numpy as np
import matplotlib.pyplot as plt
num_keypoints=[i+1 for i in range(17)]
noise=0 #标记但不可见点
w=np.array(num_keypoints)
beta=2 #控制衰减
lamda=np.exp(1/beta)+1 #让标注点数量为1的难度值D设为最大为1
p=lamda*(1-1/(1+np.exp(-np.sqrt(w-noise)/beta)))
plt.plot(w,p,lw=2)
plt.xlabel('number of keypoints with noise')
plt.ylabel('initial difficulty for instance')
plt.show()

难度系数D与遗忘程度F¶
上述曲线反映了,我们根据给定的关键点标注数量为每个实例设定了初始学习难度:
$$D_{i,0}=\lambda \left ( 1-\frac{1}{1+exp\left ( -\left ( \sqrt{k_{i}-noise_{i}} \right ) \right )} \right )$$
其中$k_{i}$表示实例数据$i$的标签中标注人体的关键点的总数量,$noise_{i}$代表实例$i$噪声标注点的数量(比如该点不可见),$\lambda$表示控制难度的尺度系数,为了控制$D_{0}$在$(0,1]$范围内,这里$\lambda$取值为$e+1$
规定遗忘程度F的取值为$[0,1]$,值越大,遗忘程度越高! 所有样本的初始遗忘程度为均为1
算法设计¶
版本 1¶
:周期循环¶
#:每个周期内打乱数据集,循环加载一个Mini—batch,计算一个mini-batch下的输出loss
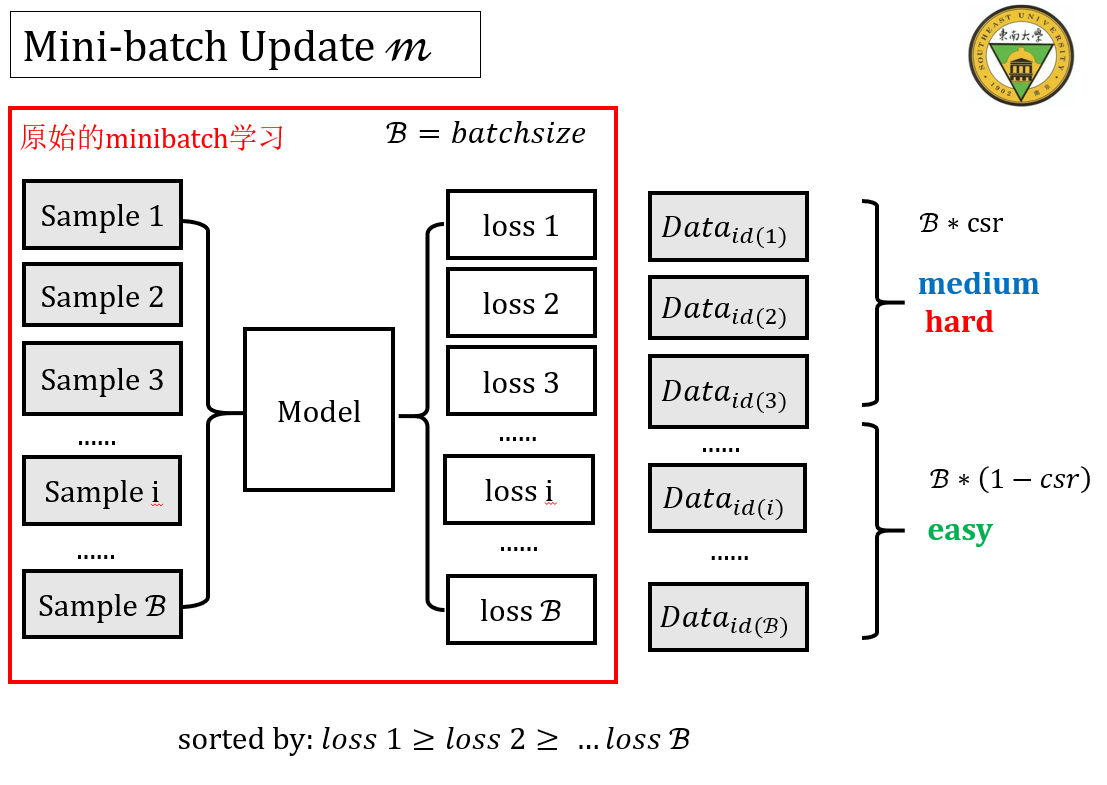
1.根据模型输出的loss,由大到小排序一个Mini-Batch中的所有样本$S_{all}$
2.按照CSR在一个Batch中选择一定比例的样本集S_{csr},考察这些样本的难度。其余样本设为S_{easy}
3.难:如果S_{csr}中样本难度较大(超过设定阈值),抛弃该样本对梯度回传的贡献,同时增加其遗忘程度的数值,增量为delta
4.中:如果S_{csr}中样本难度一般(小于设定阈值),保留该样本对梯度回传的贡献,同时减少其遗忘程度的数值,减量为delta
5.易:对于S_{easy}中的样本,保留该样本对梯度回传的贡献,同时减少其遗忘程度的数值,减量为2*delta
6.对于S_{all}的样本,重新计算其难度,新难度=1/2*(旧难度+遗忘程度)
此设计还没有将 中后期如何处理难度较大,即被抛弃次数较多的样本 考虑在内。
二次设计与实验¶
参考依据¶
A Closer Look at Memorization in Deep Networks中的一些结论:
DNN优先使用模式,而不是粗暴式的记忆学习来拟合数据,噪声数据的拟合和真实数据的拟合是存在本质区别,粗暴学习不能让模型捕捉到数据之间的模式和特征,
DNN的记忆与泛化能力取决于网络架构、优化程序以及数据本身
DNN 首先学习简单的模式,简单的样本可以作为模式学习的依据,可帮助模型更快地学习数据流形中的决策边界
数据集中存在一定比率的临界样本(critical sample ratio),临界样本的存在影响模型对数据的假设变得复杂
想法来源¶
有效的学习算法(模型+训练程序)可以为数据寻找到一个更合理的假设
DNN优先从简单样本中学习到模式,
方法是一般的,人体关键点回归是一个实际的具体应用:
a.关键点的数量和是否遮挡会带来很多噪声干扰的存在, b.数据集中样本的外观与姿态变化差异较大 c.头部关键点与身体关键点的学习难度差别也较大!
原则:¶
- 训练前期: 模型学习更简单的样本,保留一小部分难样本对梯度回传的贡献
- 训练后期: 减少模型对较困难样本学习的限制,抛弃极其困难的样本
特点:¶
每个周期间的误差学习不再保持独立,而是通过Meta属性的取值而存在前后关联,使得模型对每个迭代学习具有记忆性,即每次迭代,参考了模型的过去历史学习经验
具体设计与简单的实验(写在了PPT里面)¶
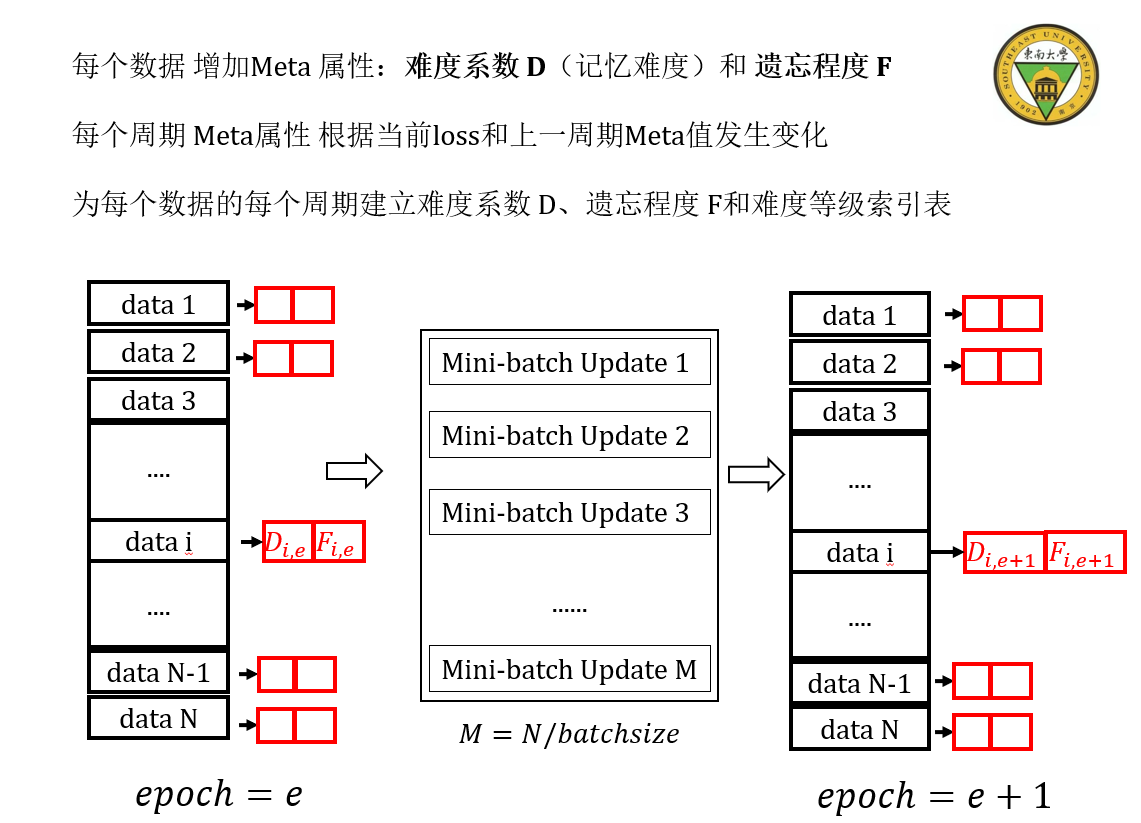

拟去掉难样本的集中学习阶段,把它渐进地覆盖到整个学习过程

新的难度系数=旧难度系数0.5+遗忘程度0.5的公式,是我人工设计,并没有什么依据或者理论做支持,我这样计算的目的是:
- 让难度系数尽可能参考上一步的难度,继续维持,但因为随着模型的学习,样本的整体难度在降低
- 让学习次数较少(遗忘程度较高)的样本保持较大的难度。只有在计算得到它的loss值较小的时候,才会让模型学习它,减少其遗忘程度,这样意味着样本的难度降低并不是来自偶然,而是模型的表示能力提升导致。
ResNet18 不同噪声等级(0,0.3,0.7)下的对比实验¶
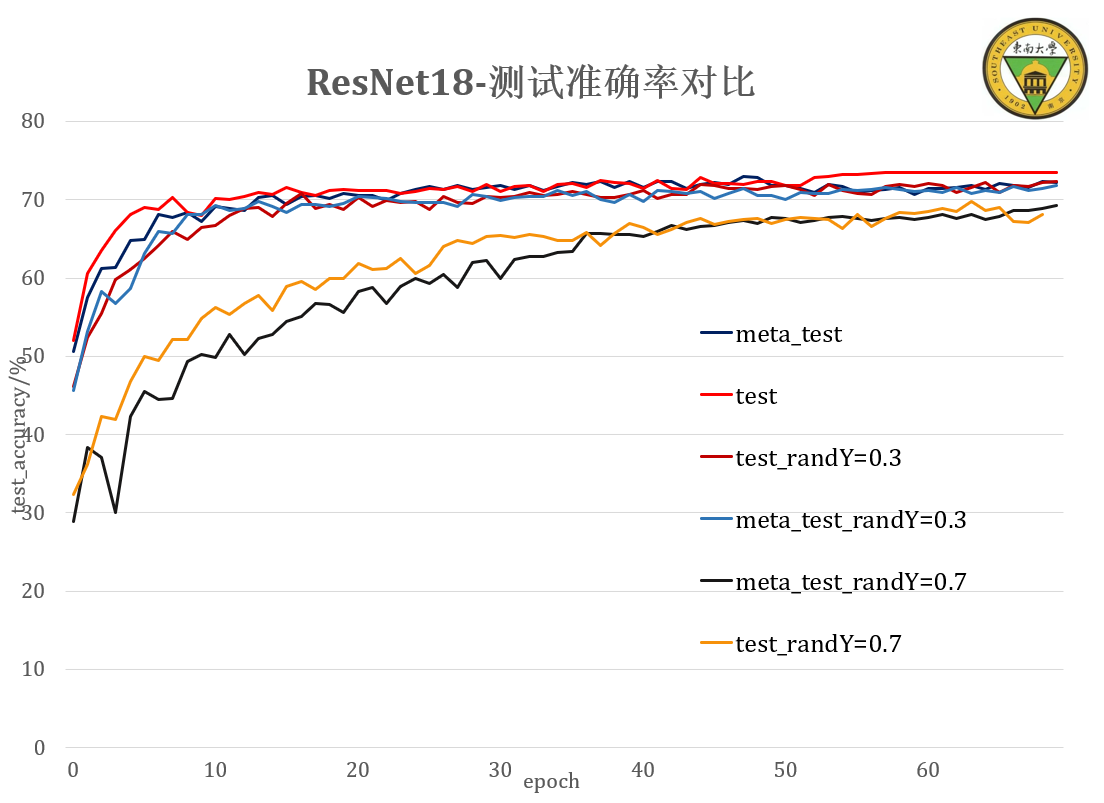
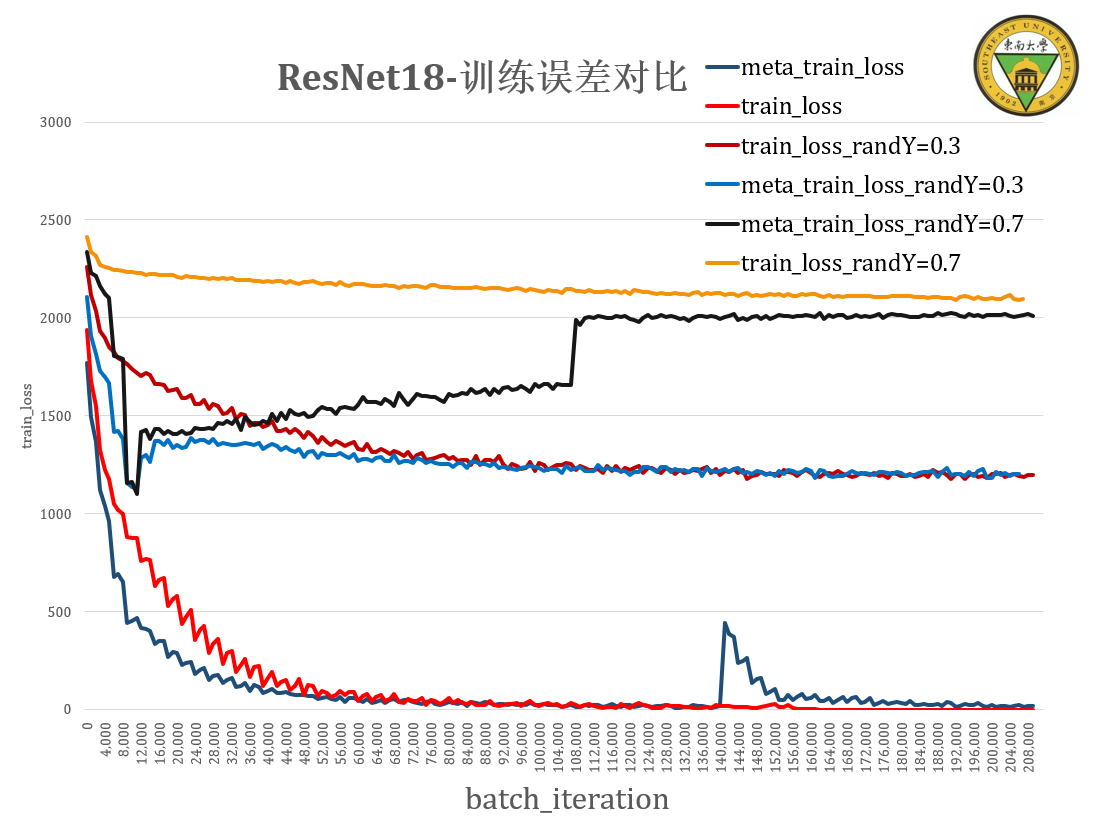
实验结果分析¶
没有达到预期效果!模型的泛化性能还是受数据本身的影响更大。但只取部分loss作梯度回传,依旧可以使得模型保持原先的泛化能力
在难度样本的loss被加入学习时,模型会出现一个短暂的性能下降,这是由于非典型(临界?)样本的突然出现让模型原本寻找的假设发生了变化。
ResNet18的有效容量不足以拟合所有的包含噪声的数据,加上训练周期迭代次数不够,带噪声的学习没有讲训练误差收敛至0附近
Loss值作为学习难度的参考是否有足够的证据,该怎么利用loss?CIFAR-10的初始难度系数我使用了随机设置,初始值是不是很影响?
算法的设计上比较粗糙,Meta属性的难度系数值的计算,是否真正代表特定样本在某个周期的实际学习难度,值得怀疑!如何更新计算难度的公式也需要进一步推敲。
下一步工作¶
考虑去除hard-learning stage 让困难样本的加入不突然,调节CSR在不同周期的大小,使得困难样本学习的加入更加平滑
应用在人体关键点任务keypoints回归的任务上,使用MSCOCO数据集,为每个样本与关键点建立难度。
初步看了MentorNet(2018 ICML)的工作,有很多可以借鉴的地方.
相关的工作self-paced learning(2010 NIPS)和在线学习 self-paced Curriculum (2015 AAAI)都强调了样本的学习顺序问题和学习难度问题,但对于单个样本的学习难度并没有准确的定义,而loss的大小跟样本学习难度是相关的,但是如何定义难度是一个难题。但直觉上和一些研究的实验结果表明,考虑样本的难度和学习顺序是可以提升模型泛化性能的。