引言¶
2018.10.6 杨森
Simple baslines for human pose estimation and tracking 这篇论文,主要针对,如何设计一个简单的深度的神经网络来高精度地估计2D人体姿态关键点,作出一个实验性质的分析与论证,并提出了针对视频中人体关键点跟踪的解决方法。
作者使用预训练的ResNet-50,100,152层网络作为特征提取的骨干网络,得到分辨率较低但是语义信息较强的特征图,然后使用转置(反)卷积的方式恢复特征尺寸,来预测Keypoints的heatmap响应值,在17个heaetmap中,取距最高峰与次高峰连线四分之一处位置为某骨架关键点位置来实现预测。
采用估计方法较为直接的自上而下的方式。 训练:采用GT_bbox区域作为神经网络的输入,通过平移、缩放等操作将bbox区域调整到固定的输入尺寸上(作者采用256x196和384x288的4:3设定) 推理:使用Faster-RCNN在val或者test集上的人体检测bbox结果,然后具体估计该区域内的人体姿态关键点
接下来,我会参考作者的论述与实验分析,提出我自己的一些观点
入手¶
此论文的模型在COCO TEST-DEV上达到mAP=73.8的优异效果。
作者在论文中做出了很多对比实验,从实验的角度说明了一些简单的设计原则:大尺寸输入、较深的网络、反卷积替代跳层连接、较大的卷积核等可以提高性能。
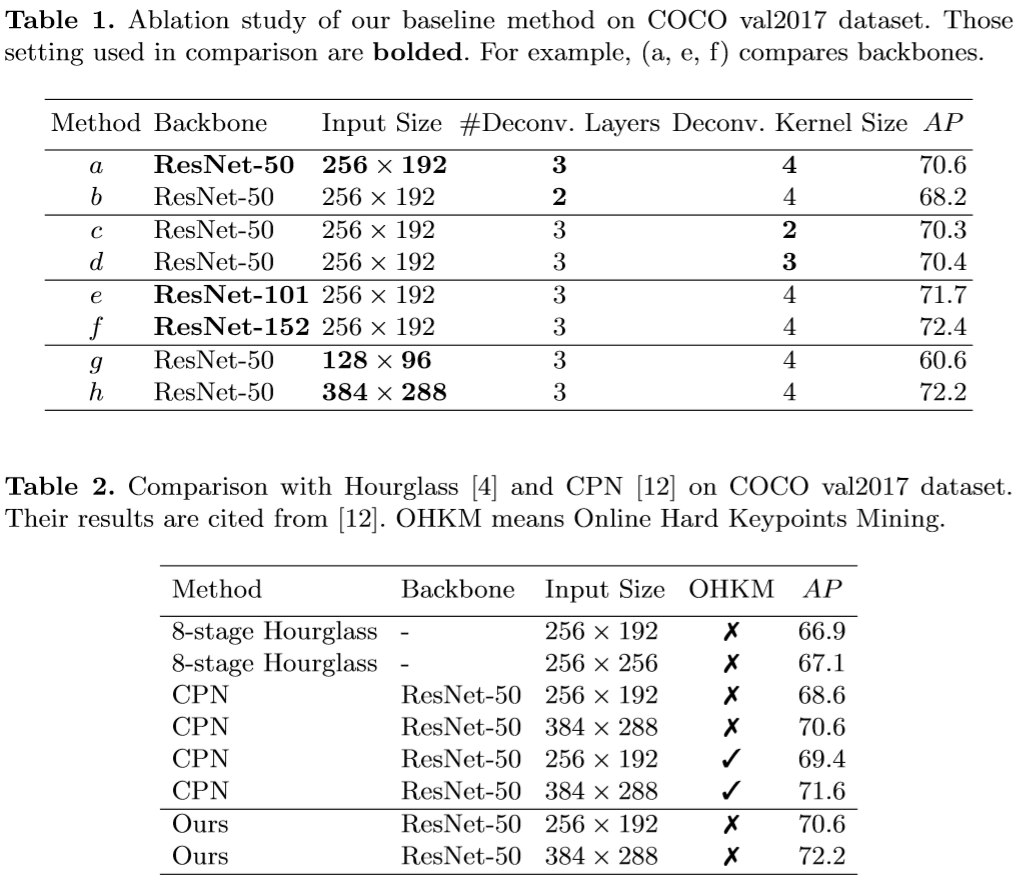
作者公布了源码,其代码封装特性特别好,适合作不同模块的修改与对比实验。
在数据集的预处理上,也很精心,取得如此良好的性能,也离不开数据处理环节。一些简单噪声处理、数据增强手段被使用。 而在数据处理方面,大多研究者还是从经验出发,也多以实验科学的方式来描述自己的处理方式。
鲁棒拟合的简单原则¶
直觉上,我这里主要从数据与神经网络模型拟合性质的角度出发,来考虑在训练模型与测试模型时,针对数据集和单个数据处理的一些简单的原则:
为了更加鲁棒地拟合与泛化,尽可能同时消除数据集中数据和标签中的噪声信息对于训练模型、测试模型时的负面影响,让神经网络处理更加具有一致性的数据,使模型更加快速地学习,增强模型对几何不变性特征的识别能力,减少对抗样本的干扰。
我们的具体目标为:
- 在训练模型时,尝试给模型制造一个在测试或泛化识别时所面对的相似的噪声干扰情景。(因为CNN 对旋转和尺度不具备不变性 ,那么旋转和尺度的多边形会带来大量的噪声干扰)
- 在测试模型时,通过一些手段将输入数据转化为训练时模型所面对的常见一般形式的数据与标注,即将噪声限制在可控的范围内
- 在模型对一般人体形状模式具备一定的泛化识别能力后,我们不再限制的噪声的正常存在,并通过一些数据增强的手段来引入噪声,来使得模型具备较好的鲁棒性。
- 网络结构设计上也要精简,将提取多层次的深度的特征相融合的思想体验在结构设计上,并且同时将上述3条原则蕴含在内。
以上述原则指导下,可以设计出多种处理方式:
- 比如,训练时使输入的人体bbox尺寸尽可能一致,测试时按与训练所用的同一准则对检测的bbox进行变换。具体:可以使用Spatial Transfer Networl网络进行类似旋转、尺度变化的一致变化,增强模型对几何不变性的特征的提取能力。
- 比如,在训练到达一定周期,mAP识别率高于一定阈值后,我们再加入数据增强。而不是单纯地使用正则化使得模型具备泛化能力,我们让模型从本质上去认识数据中的模式。
比如,在一个mini-batch中,抛弃一定比率的大loss样本,先认定小loss样本为纯净样本,有点像AdBoost理念或者OHEM(在线难例挖掘)的逆向思维,在一定程度上属于Meta-learning的范畴。具体:定义不同难度,我们可以根据标注点的数量,优先学习标注点数量多的图像。Adaptive Batch!
比如,针对处理数据与标签噪声问题入手,在原基础上加入一个修正bbox位置的函数,来解决keypoints不在bbox的噪声干扰问题,见bbox_retify() 函数
- 比如,......
def bbox_retify(self,width,height,bbox,keypoints,margin=0):
"""
`Author`: Yang Sen \n
`Function`: use bbox_retify() function to let the bbox cover all visible keypoints \n
`Purpose`: reduce the label noise resulting from some visible (or invisible) keypoints not in bbox
"""
kps = np.array(keypoints).reshape(-1, 3) #array([[x1,y1,1],[],[x17,y17,1]]]
# for all keypoints: kps[kps[:,2]>0]
# only for visible keypoints: kps[kps[:,2]==2]
border = kps[kps[:,2] >=1 ]
if sum(kps[:,2] >=1) > 0:
a, b = min(border[:,0].min(),bbox[0]), min(border[:,1].min(), bbox[1])
c, d = max(border[:,0].max(),bbox[0]+bbox[2]), max(border[:,1].max(),bbox[1]+bbox[3])
assert abs(margin)<20 ,"margin is too large"
a,b,c,d=max(0,a-margin),max(0,b-margin),min(width,c+margin),min(height,d+margin)
return [a,b,c-a,d-b]
else:
return bbox
在作者源代码加入上述函数的 实际效果:

129个周期时:在Val2017验证集上,达到AP=0.75
另外,我们再考虑一点,作者的用ResNet作为骨架网络,没有加入跳层连接仅使用反卷积,这样的设计为什么有效?
神经网络中的数据流动是一种信息重整的过程¶
神经网络是一种可以将原始图像信息重整为我们想在其中抽象出的目标信息,目标信息的拟合通过损失函数的梯度下降来实现。
原始图像数据信息,在神经网络中不同的层中,以不同形式的特征图来表达。下面4条是我的观点:
- 特征图的尺寸大小决定了特征图信息中位置信息容量的上限
- 特征图的通道数量决定了特征图信息中语义信息容量的上限
- 位置信息容量和语义信息容量之间存在相互制约的关系
- 跨特征图之间的信息融合可以帮助在不同特征等级下寻找抽象的模式
在我的理解看来,ResNet本身的残差模块中的旁路设计,本身就等效于不同层次特征图之间的信息整合,从有向图的数据流动的拓朴结构上看,它一定程度上等价于stacked Hourglass或者FPN中的跨层连接,它们在共同做一件事情,整合不同特征等级下的特征图信息,而此论文中的反卷积只是为了恢复heatmap的大小,使得位置的预测更加精细一点。
所以我打算再次精简这种思想下的网络设计。
想法很纯粹,一切从“简”¶
不仅数据上简单一致,不复杂,灵活处理复杂噪声的干扰
结构设计上也要简单,只要将提取多层次的深度的特征的思想蕴含在内,以简洁的设计形式表达出来,那么直觉上是可行有效的。
我的方法是:在ResNet152层中引入dilation,保留ResNet152中,降低原输入分辨率至1/4的特征提取结构,在其产生的2048个通道的特征图上,使用空洞卷积空间金字塔池化层(Atrous Spatial Pyramid Pooling ,ASPP),输出固定尺寸的Heatmap,不再使用上采样操作。
ASPP在论文:DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs,它发表在2017年TPAMI上。ECCV2018的PersonLab论文中也使用了这一结构。
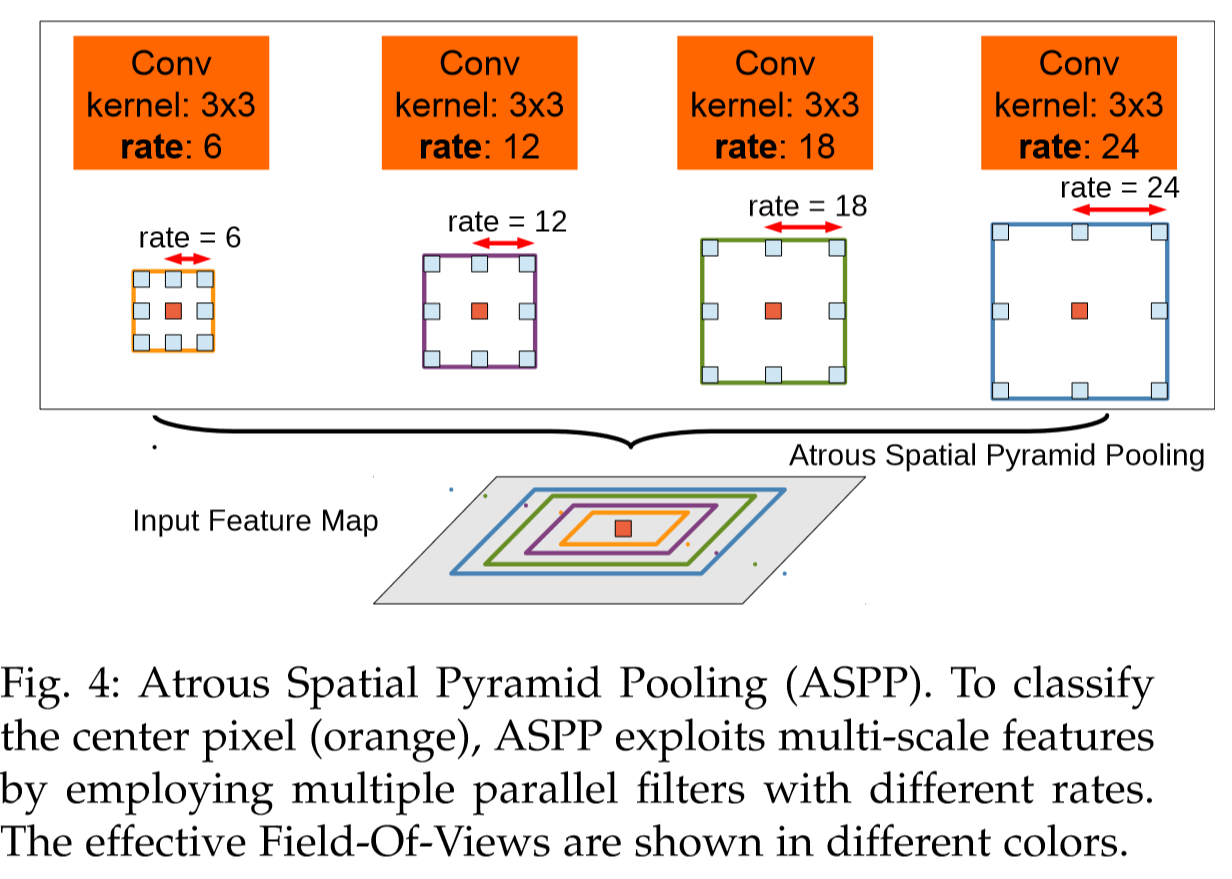
为什么使用空洞卷积空间金字塔池化?¶
- 空洞卷积扩大感受野的同时尽可能减少精确位置信息的丢失!因为卷积核覆盖尺寸提高的同时还能保持较大的输出heatmap的尺寸
$$KernelSize_{Atrous}=KernelSize+(KernelSize-1)*(AtrousRate-1)$$
- 从RCNN系列中启发,运用多尺度的空间金字塔池化来寻找图像中不同人体尺寸的共同一致特征
- 空洞卷积在语义分割或者叫密集预测中有较好的效果,那么直觉上,在人体关键点heatmap图上也可使用。
如何使用空洞卷积?¶
Pytorch的卷积nn.Conv2d其实已经将空洞卷积功能包含在内(Atrous convolution或者叫扩张卷积,dilation convolution) 这个网页里面,可以比较形象地说明这个空洞卷积的操作!
使用空洞卷积,特征图尺寸如何变化,需要一个准确的计算,好来完成匹配。下面我来介绍:
特征图卷积操作,尺寸计算万能公式
- Input:$(N, C_{in}, H_{in}, W_{in})$
- Output:$(N, C_{out}, H_{out}, W_{out})$
$\begin{align}\begin{aligned}H_{out} = \left\lfloor\frac{H_{in} + 2 \times \text{padding}[0] - \text{dilation}[0] \times (\text{kernel_size}[0] - 1) - 1}{\text{stride}[0]} + 1\right\rfloor\\W_{out} = \left\lfloor\frac{W_{in} + 2 \times \text{padding}[1] - \text{dilation}[1] \times (\text{kernel_size}[1] - 1) - 1}{\text{stride}[1]} + 1\right\rfloor\end{aligned}\end{align}$
其中: dilation (int or tuple, optional) – Spacing between kernel elements. Default: 1
经过正常卷积得到的特征图,可以通过反卷积torch.nn.ConvTranspose2d()映射回原始输入可能对应几种不同的输入尺寸,而ouput_padding就是为了确定原始输入的尺寸大小而设 的参数
$H_{out} = (H_{in} - 1) \times \text{stride}[0] - 2 \times \text{padding}[0] + \text{kernel_size}[0] + \text{output_padding}[0]$ $W_{out} = (W_{in} - 1) \times \text{stride}[1] - 2 \times \text{padding}[1] + \text{kernel_size}[1] + \text{output_padding}[1]$
ResNet_DeepLab¶
import torch.nn as nn
class ResNet_DeepLab(nn.Module):
def __init__(self, block, layers,NoLabels):
self.inplanes = 64
super(ResNet, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3,
bias=False)
# 特征图尺寸 1/2
self.bn1 = nn.BatchNorm2d(64,affine = affine_par)
for i in self.bn1.parameters():
i.requires_grad = False
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1, ceil_mode=True) # change
# 特征图尺寸 1/4
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=1) # stride 2->1
# 特征图尺寸 1/4
self.layer3 = self._make_layer(block, 256, layers[2], stride=1, dilation__ = 2) # stride 2->1
# 特征图尺寸 1/4
self.layer4 = self._make_layer(block, 512, layers[3], stride=1, dilation__ = 4) # stride 2->1
# 特征图尺寸 1/4
# 空洞卷积空间金字塔池化
# 空洞卷积核的比率r=3,6,8,12,卷积核的尺寸k=3
#实际卷积核尺寸大小Kernel_Atrous=k+(k-1)(r-1)
self.layer5 = self._make_pred_layer(Classifier_Module, [3,6,8,12],[3,6,8,12],NoLabels)
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, 0.01)
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
# for i in m.parameters():
# i.requires_grad = False
def _make_layer(self, block, planes, blocks, stride=1,dilation__ = 1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion or dilation__ == 2 or dilation__ == 4:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * block.expansion,affine = affine_par),
)
for i in downsample._modules['1'].parameters():
i.requires_grad = False
layers = []
layers.append(block(self.inplanes, planes, stride,dilation_=dilation__, downsample = downsample ))
self.inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(self.inplanes, planes,dilation_=dilation__))
return nn.Sequential(*layers)
def _make_pred_layer(self,block, dilation_series, padding_series,NoLabels):
return block(dilation_series,padding_series,NoLabels)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.layer5(x)
return x
难度自适应批处理 Ada-Batch
原因:参数多与梯度算法,导致模型太容易记住数据集中的噪声。
1Understanding deep learning requires rethinking generalization. (ICLR), 2017.
2Arpit, Devansh et al. “A Closer Look at Memorization in Deep Networks.” ICML (2017)
在每个Batch里计算出loss之后,根据loss大小排序(loss代表了模型的认知偏差,偏差越大,表明模型对数据中一致性的提取具备难度,这是由部分难度大的数据的存在所导致的,但我们不可以抛弃这样有难度的数据,应该放到后面进行学习) ,从小到大,前30%为“易”,40%为“中”,30%为"难",然后给每个数据每个周期建立索引,每个索引代表该周期时模型处理该样本的难度。每次迭代周期时 查看排名靠后40%的样本,先查询是否之前的周期索引中是否出现过 "简单"索引?
这样设计的话,模型就可以记住数据的历史学习难易程度,根据当前难度,来调整学习规则,最直接的做法就是,在训练的前期,尽可能喂给模型更简单的数据,在训练的中后期,喂给模型更多较难的数据,同时,保证模型不遗忘对简单样本的学习拟合。基于以上原则,可以设计出简单高效的算法。接下来的工作我会考虑设计这个算法。??
import torch.nn.functional as F
class STN_Deeplab_PoseNet(ResNet_DeepLab):
def __init__(self,block, layers, NoLabels):
super(STN_Deeplab_PoseNet, self).__init__(block, layers, NoLabels)
#self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
#self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
##self.conv2_drop = nn.Dropout2d()
#self.fc1 = nn.Linear(320, 50)
#self.fc2 = nn.Linear(50, 10)
# Spatial transformer localization-network
self.localization = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=7),
nn.MaxPool2d(2, stride=2),
nn.ReLU(True),
nn.Conv2d(64, 128, kernel_size=5),
nn.MaxPool2d(2, stride=2),
nn.ReLU(True)
nn.Conv2d(128, 64, kernel_size=3),
nn.MaxPool2d(2, stride=2),
nn.ReLU(True)
)
# Regressor for the 3 * 2 affine matrix
self.fc_loc = nn.Sequential(
nn.Linear(64 * 46 * 34, 32),
nn.ReLU(True),
nn.Linear(32, 3 * 2)
)
# Initialize the weights/bias with identity transformation
self.fc_loc[2].weight.data.zero_()
self.fc_loc[2].bias.data.copy_(torch.tensor([1, 0, 0, 0, 1, 0], dtype=torch.float))
# Spatial transformer network forward function
def stn(self, x):
xs = self.localization(x)
xs = xs.view(-1, 64 * 46 * 34)
theta = self.fc_loc(xs)
theta = theta.view(-1, 2, 3)
grid = F.affine_grid(theta, x.size())
x = F.grid_sample(x, grid)
return x
def forward(self, x):
# transform the input
x = self.stn(x)
# Perform the usual forward pass
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.layer5(x)
return x